|
I am a Ph.D student at GeWu-Lab, Gaoling School of Artificial Intelligence, Renmin University of China. I am advised by Prof. Di Hu. My research interests focus on multimodal learning, including multimodal learning mechanism and MLLMs. I received my bachelor's degree in Computer Science and Technology from University of Electronic Science and Technology of China (UESTC). Had a wondeful time with my friends in Chengdu, China, from 2017-2021. |

|
|
[2026-03] One paper accepted by CVPR, thanks to all co-authors! [2025-10] Organized the first online workshop of BML community! Thanks to TechBeat and all speakers! [2025-09] MokA is accepted by NeurIPS as an Oral paper! Thanks to all co-authors! [2025-06] Release our new PEFT pipeline for MLLMs, MokA! [Project page] [2025-06] Attended student workshop @ VALSE 2025 in Zhuhai! [2025-05] One paper accepted by ICML, thanks to all co-authors! [2025-03] Two paper accepted by CVPR, thanks to all co-authors! [2025-02] Awarded the Baidu Scholarship (10 Ph.D students worldwide)! [2024-12] Awarded the China National Scholarship for Ph.D student! [2024-12] Attended the Global PhD Gathering @ 2024 Pujiang AI Conference in Shanghai! [2024-11] Gave a talk about "Balanced multimodal learning" @ Virginia Tech! Thanks the invitation from Prof. Chris Thomas! [2024-09] One paper accepted by T-PAMI, thanks to all co-authors! [2024-07] Gave a talk about "Balanced multimodal learning" @ TechBeat! [Record] [2024-07] One paper accepted by ECCV, thanks to all co-authors! [2024-05] We release a survey about fusion of low-quality multimodal data! [arXiv] [2024-05] One paper accepted by ICML, thanks to all co-authors! [2024-02] One paper accepted by CVPR, thanks to all co-authors! [2024-01] One paper accepted by ICLR, thanks to all co-authors! [2023-12] Start visiting in Human Sensing Lab @ CMU! [2023-10] One paper accepted by Pattern Recognition, thanks to all co-authors! [2022-08] We release a survey about recent advances in audio-visual learning! [website] [2022-05] Gave a talk @ 2022 BAAI Conference . Please find slides here! [2022-03] Two papers accepted by CVPR, thanks to all co-authors! [2021-12] One paper accepted by T-PAMI, thanks to all co-authors! [2021-06] Graduate from University of Electronic Science and Technology of China (UESTC)! |
|
• Baidu Scholarship (10 Ph.D students worldwide) , 2024. • China National Scholarship for Ph.D student (highest student honor in China) , 2024. • Outstanding Graduate of Sichuan province (highest honor for graduates set by Sichuan province), 2021. • Outstanding Graduate of University of Electronic Science and Technology of China, 2021. |
|
Interested in the inherent learning mechanism of perceiving, formulating, and understanding the environment with heterogeneous information from multiple modalities, e.g., vision, sound, text. Part 1. Focus on building Multimodal LLMs by considering the characteristics of diverse multimodal scenarios. For now, we have provided a new PEFT pipeline for MLLMs, MokA, which ensures both cross-modal and unimodal adaptation. MokA has been accepted and selected as an ORAL paper by NeurIPS 2025. Part 2. In the paper presented at CVPR 2022 (ORAL), introduce the research topic of "Balanced Multimodal Learning". Highlight a pervasive issue in multimodal learning, where information utilization of certain modality can be undesirably suppressed by others. Then conduct a series of systematic studies to alleviate this issue, covering empirical observations, algorithms, and theoretical analysis. 
|
|
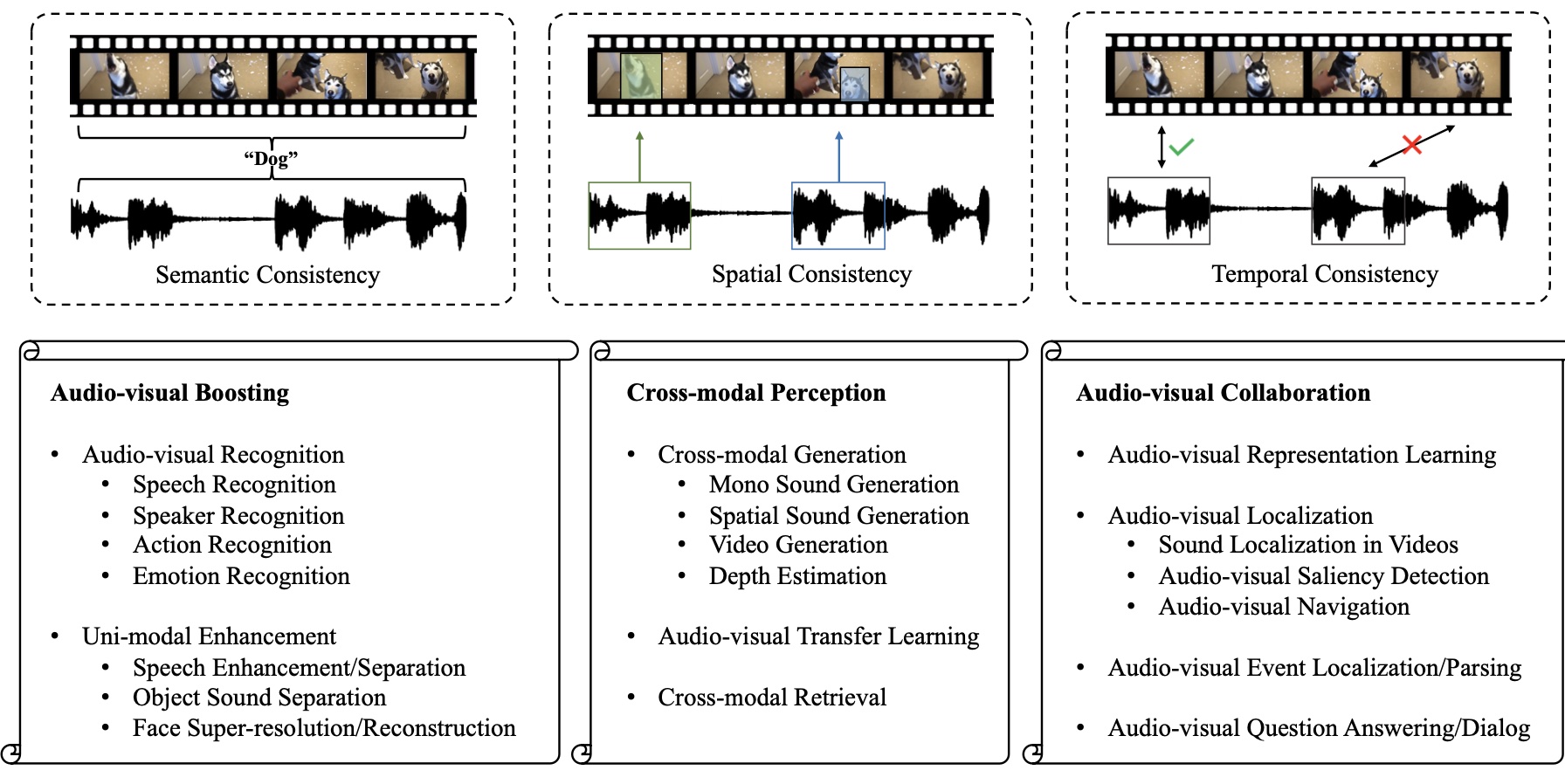
Yake Wei, Di Hu, Yapeng Tian, Xuelong Li arXiv / website / awesome list A systematical survey about the audio-visual learning field. |
|
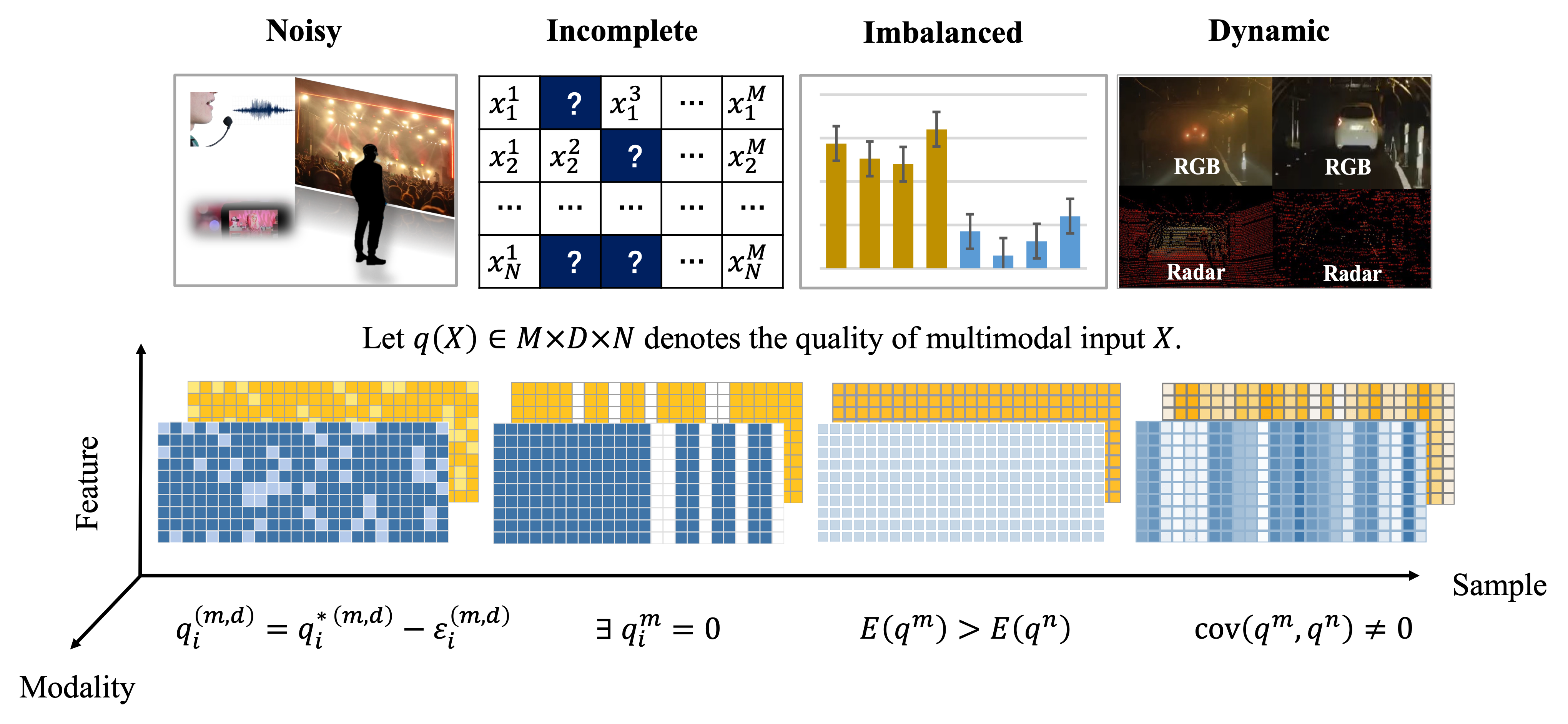
Qingyang Zhang, Yake Wei, Zongbo Han, Huazhu Fu, Xi Peng, Cheng Deng, Qinghua Hu, Cai Xu, Jie Wen, Di Hu, Changqing Zhang arXiv / awesome list A systematical survey about fusion of low-quality multimodal data. |
|
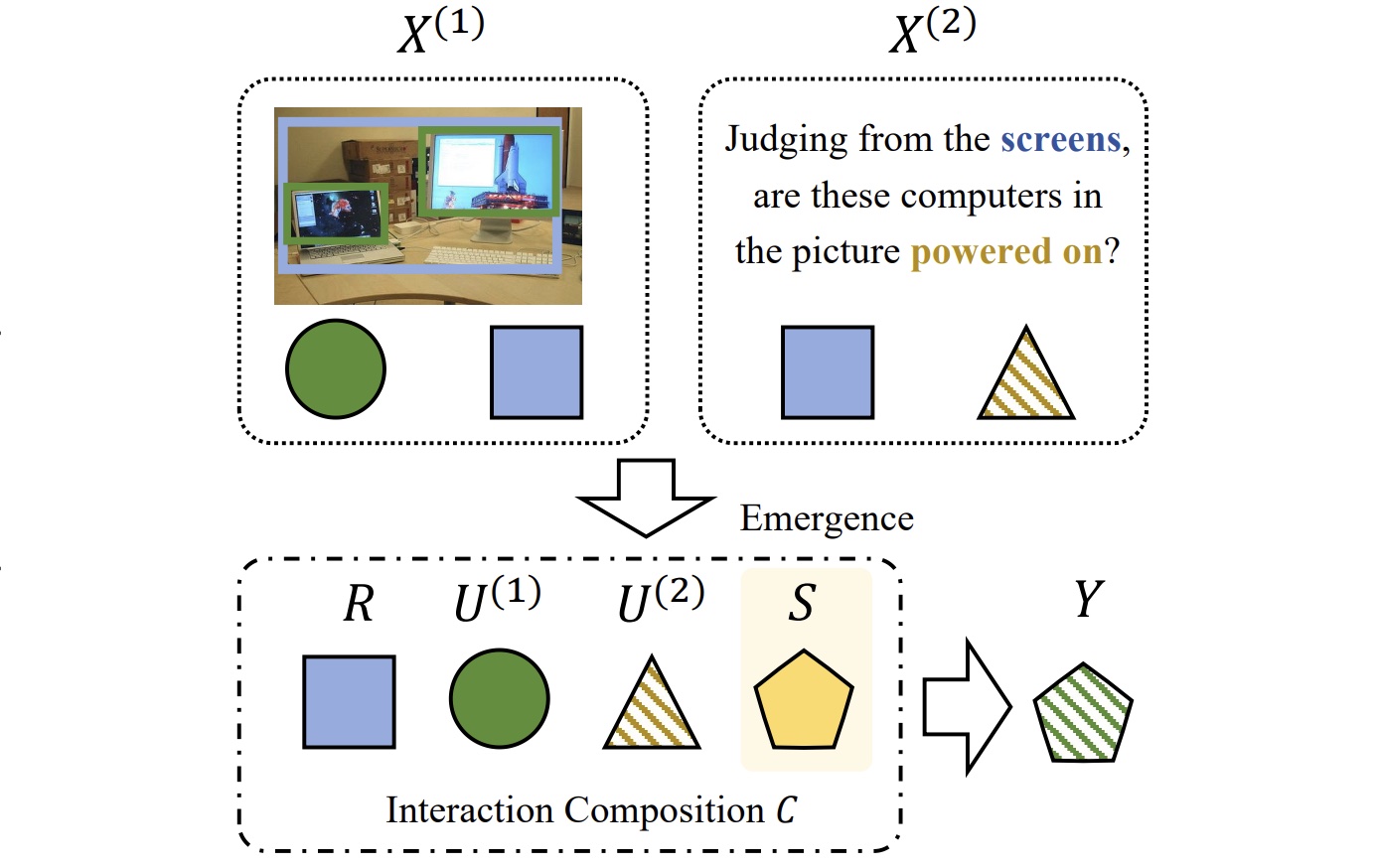
Zequn Yang, Yake Wei, Haotian Ni, Zhihao Xu, Di Hu CVPR, 2026 Distinguishes and strengthens multimodal interactions within the data. |

|
Yake Wei, Yu Miao, Dongzhan Zhou, Di Hu NeurIPS, 2025 (Oral Presentation, 1.46% of accepted papers) Project page A new PEFT pipeline for MLLMs, ensuring both unimodal and cross-modal adaptation. |

|
Haotian Ni, Yake Wei, Hang Liu, Gong Chen, Chong Peng, Hao Lin, Di Hu ICML, 2025 arXiv / code Rebalance the attention score and revive cooperation dynamics between modalities in Transformer. |
|
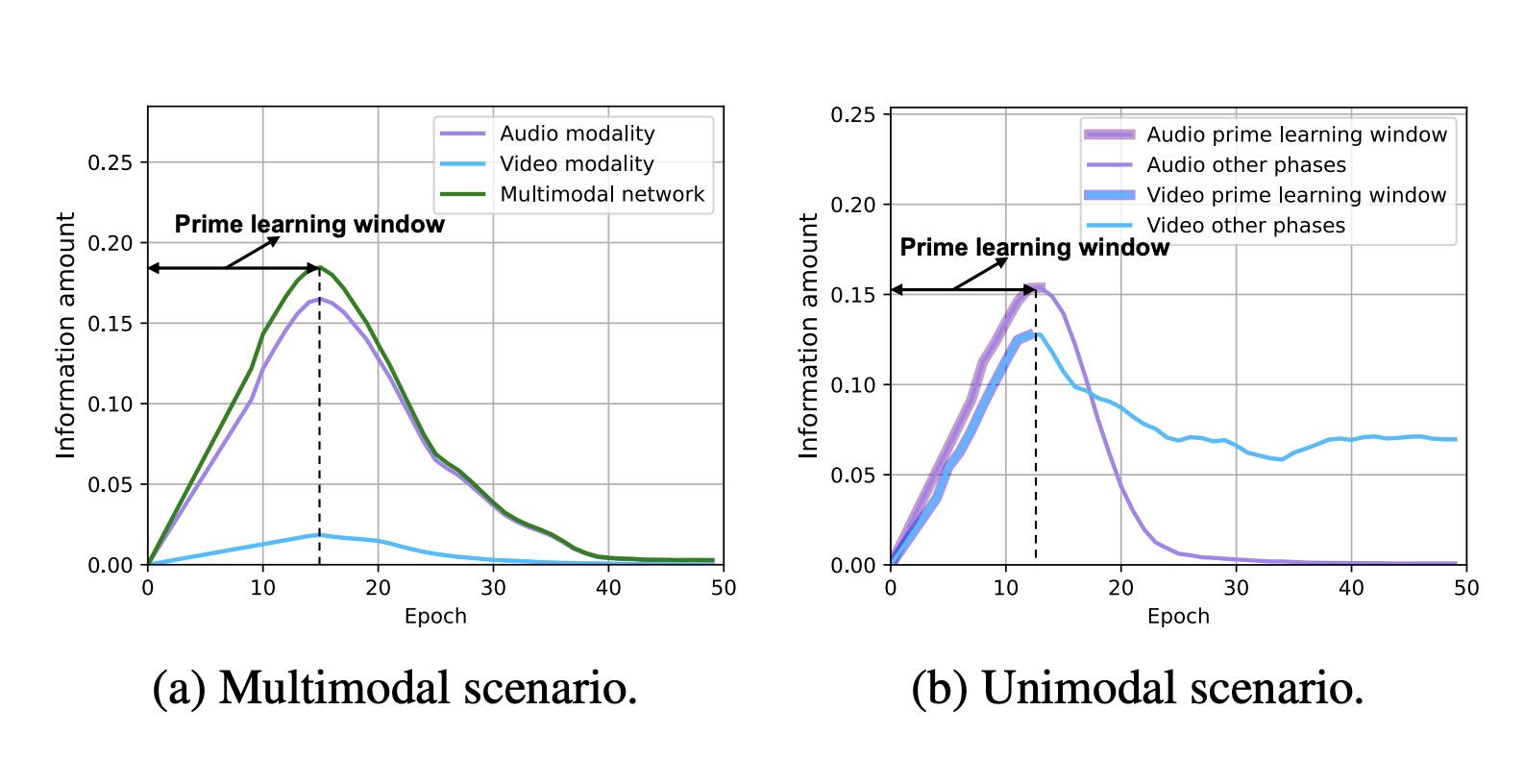
Chengxiang Huang*, Yake Wei*, Zequn Yang, Di Hu CVPR, 2025 arXiv / code Analyze and modulate information acquisition process during multimodal training process. |
|
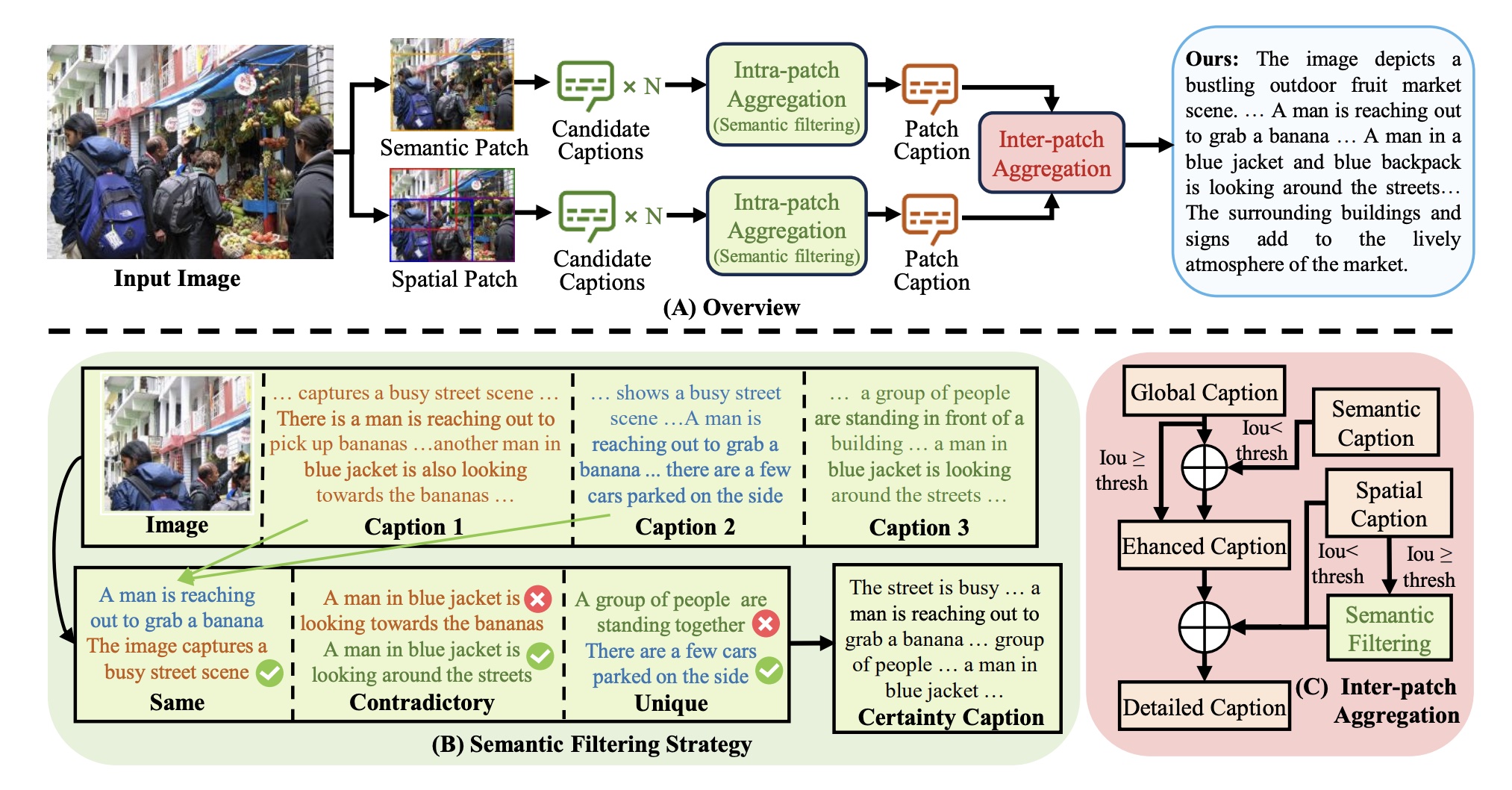
Ruotian Peng, Haiying He, Yake Wei, Yandong Wen, Di Hu CVPR, 2025 arXiv / code Generate high-quality fine-grained image caption by divide-then-aggregate strategy. |
|
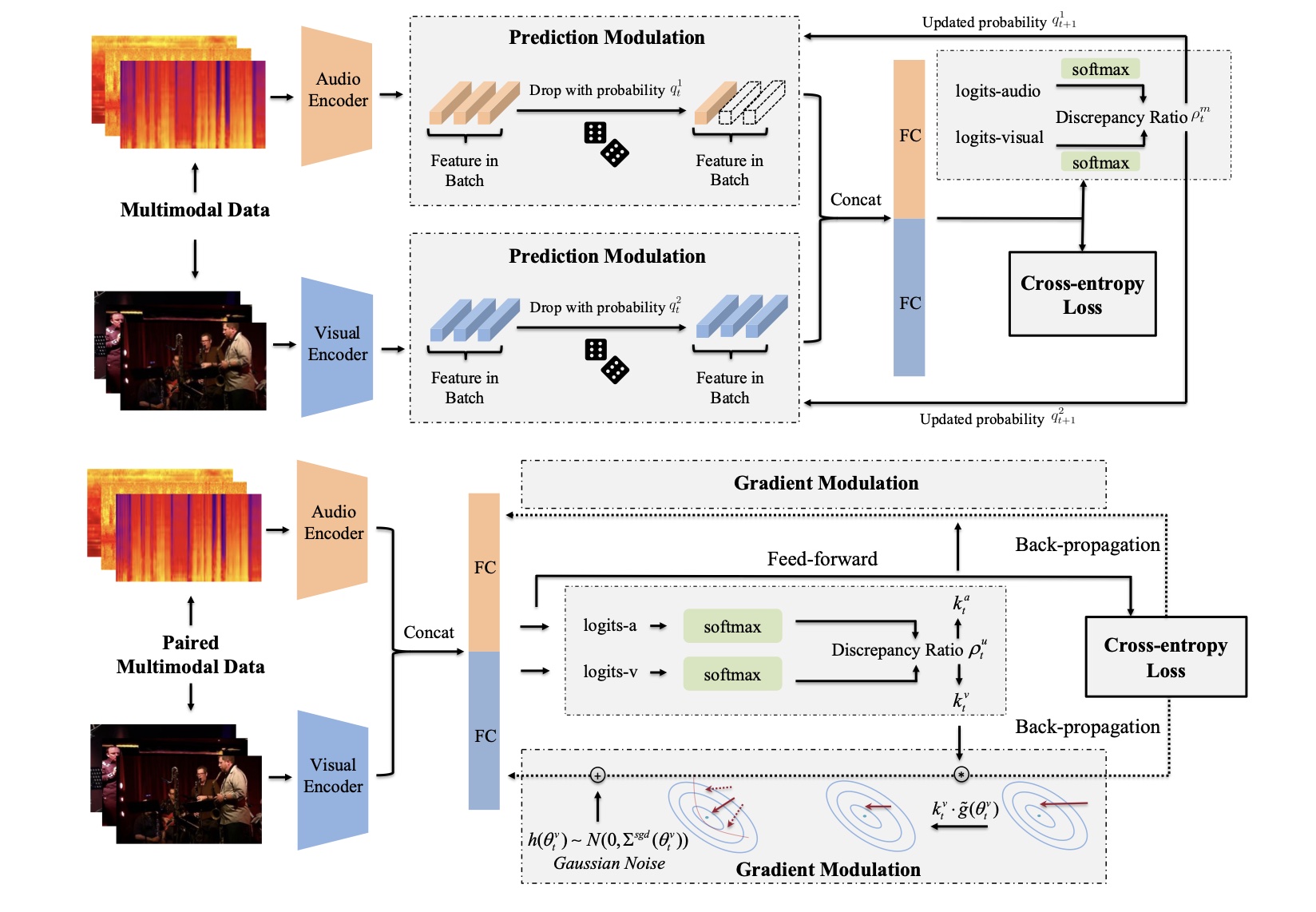
Yake Wei, Di Hu, Henghui Du, Ji-Rong Wen P.S. Thanks the valuable help from Zequn Yang T-PAMI, 2024 arXiv / code Analyze and modulate imbalanced unimodal learning from both feed-forward and back-propagation stage. |
|
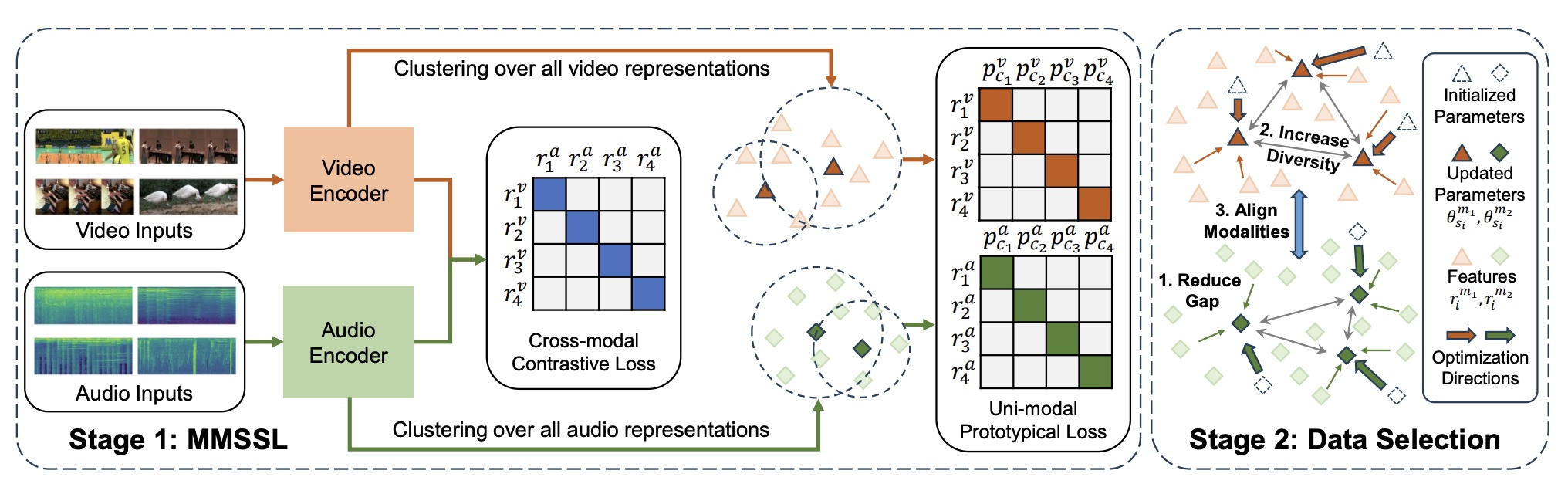
Meng Shen, Yake Wei, Jianxiong Yin, Deepu Rajan, Di Hu, Simon See ACM MM Asia, 2024 paper Improve the quality of selected multimodal data pairs in active learning. |
|
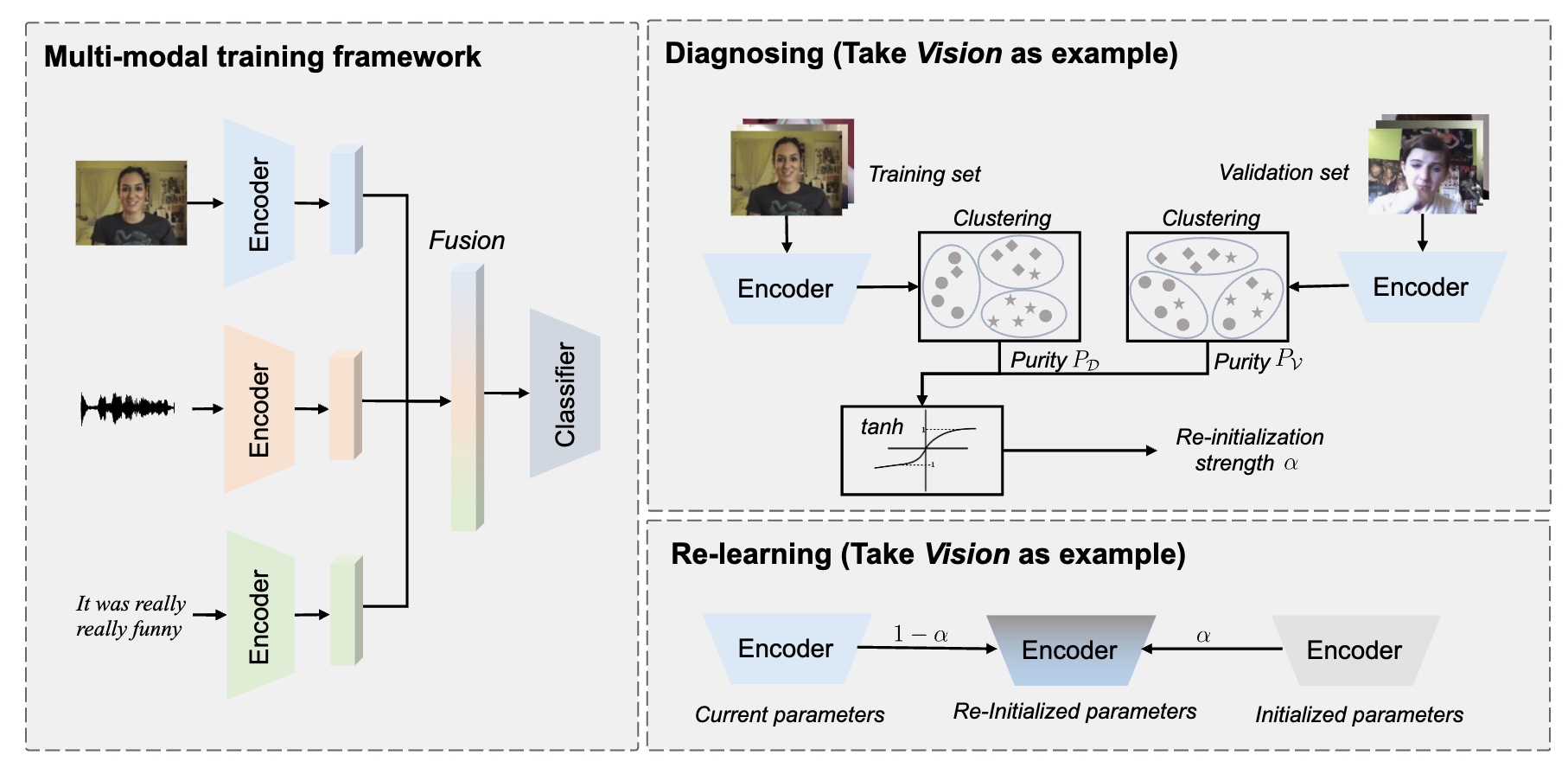
Yake Wei, Siwei Li, Ruoxuan Feng, Di Hu ECCV, 2024 arXiv / code Dynimically re-initialize unimodal encoder to enhance both worse-learnt and well-learnt modalities. |
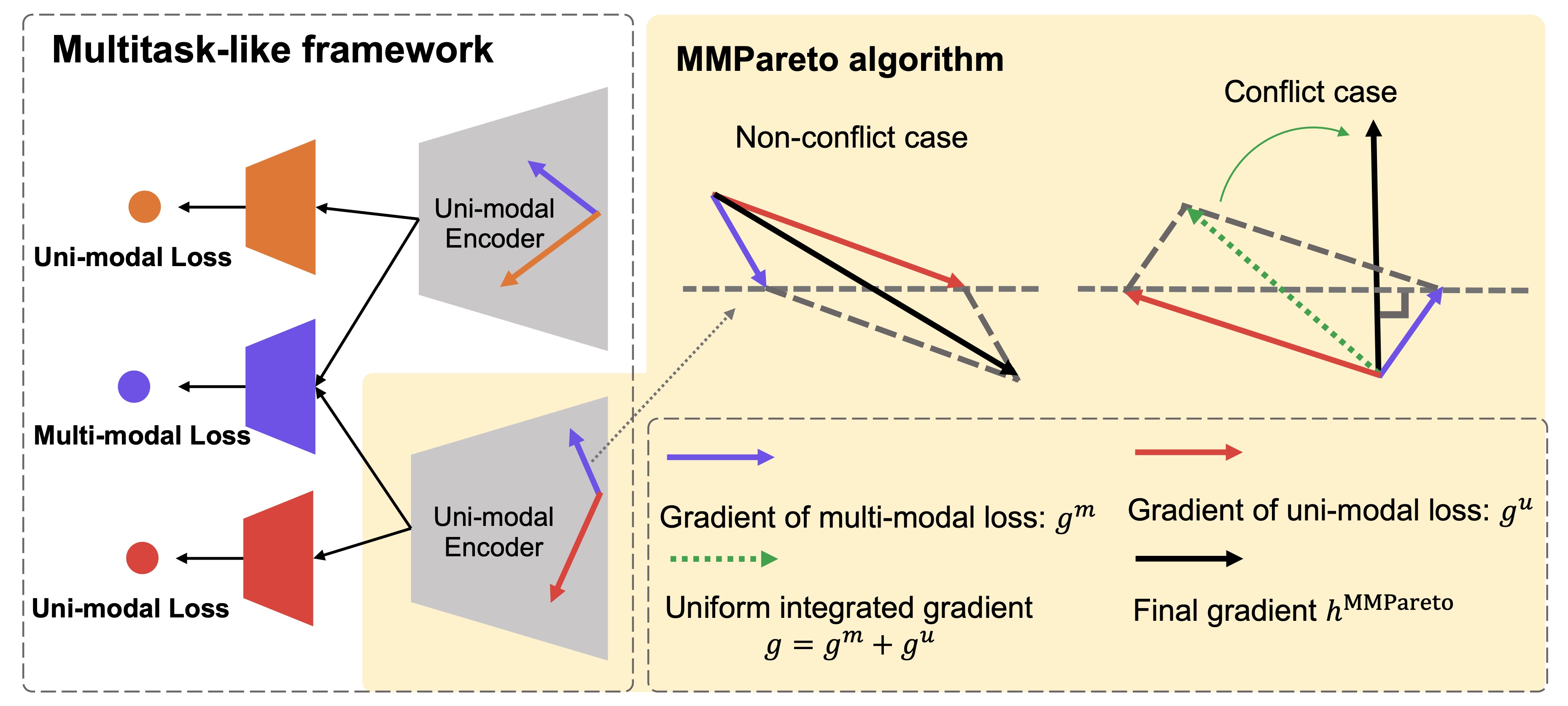
|
Yake Wei, Di Hu ICML, 2024 arXiv / code Solve conflicts between multimodal and unimodal gradients under multimodal scenarios. |
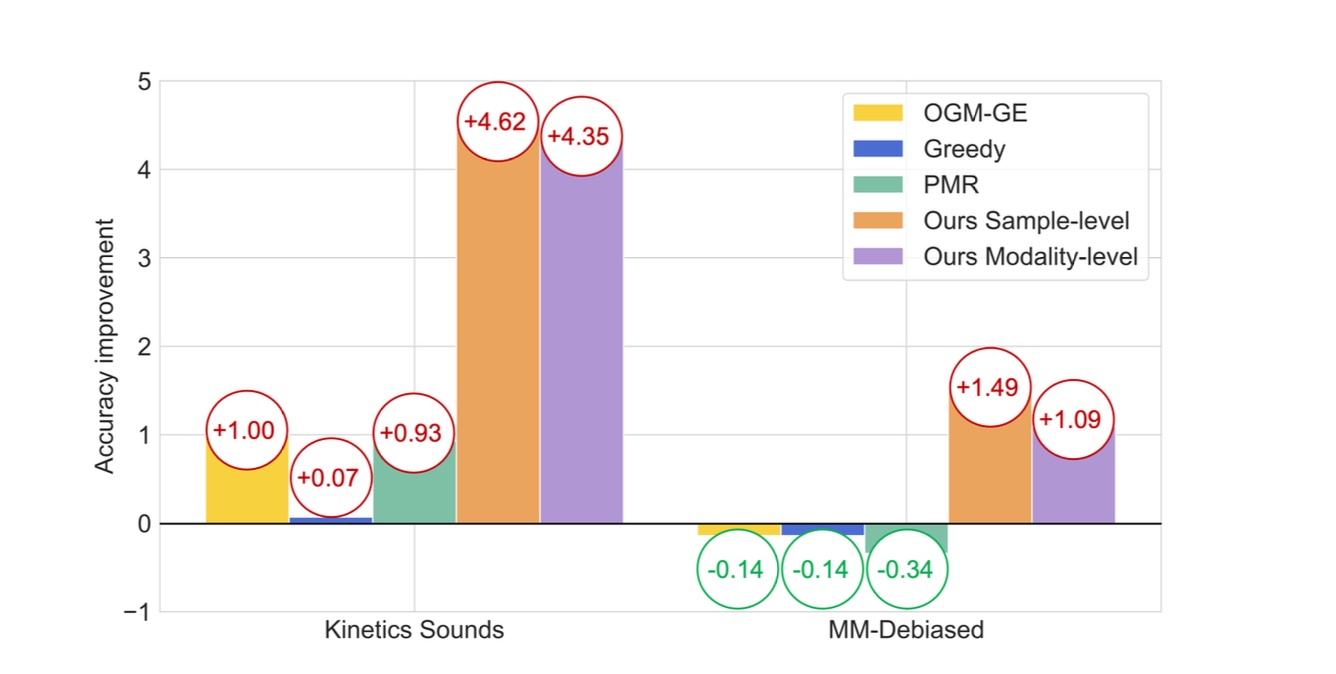
|
Yake Wei, Ruoxuan Feng, Zihe Wang, Di Hu CVPR, 2024 arXiv / code Observe and improve the fine-grained cooperation between modalities at sample-level. |
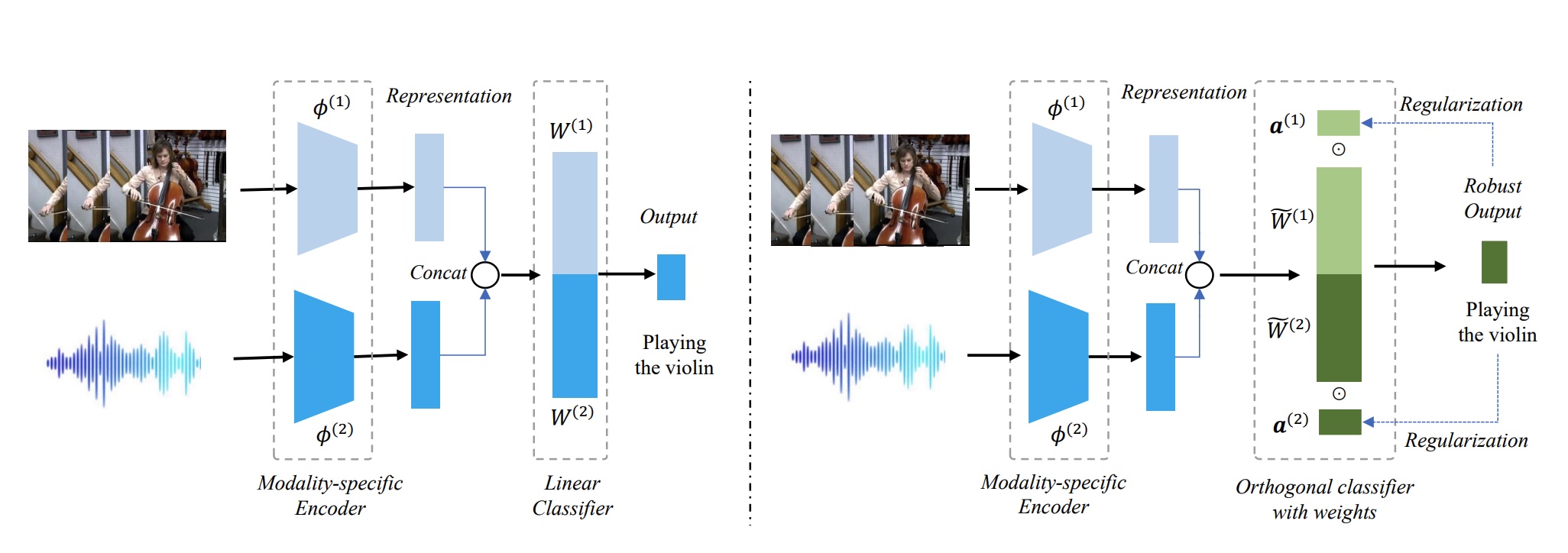
|
Zequn Yang, Yake Wei, Ce Liang, Di Hu ICLR, 2024 arXiv / code Analyze essential components for multimodal robustness and delve into the limitations imposed by modality preference. |
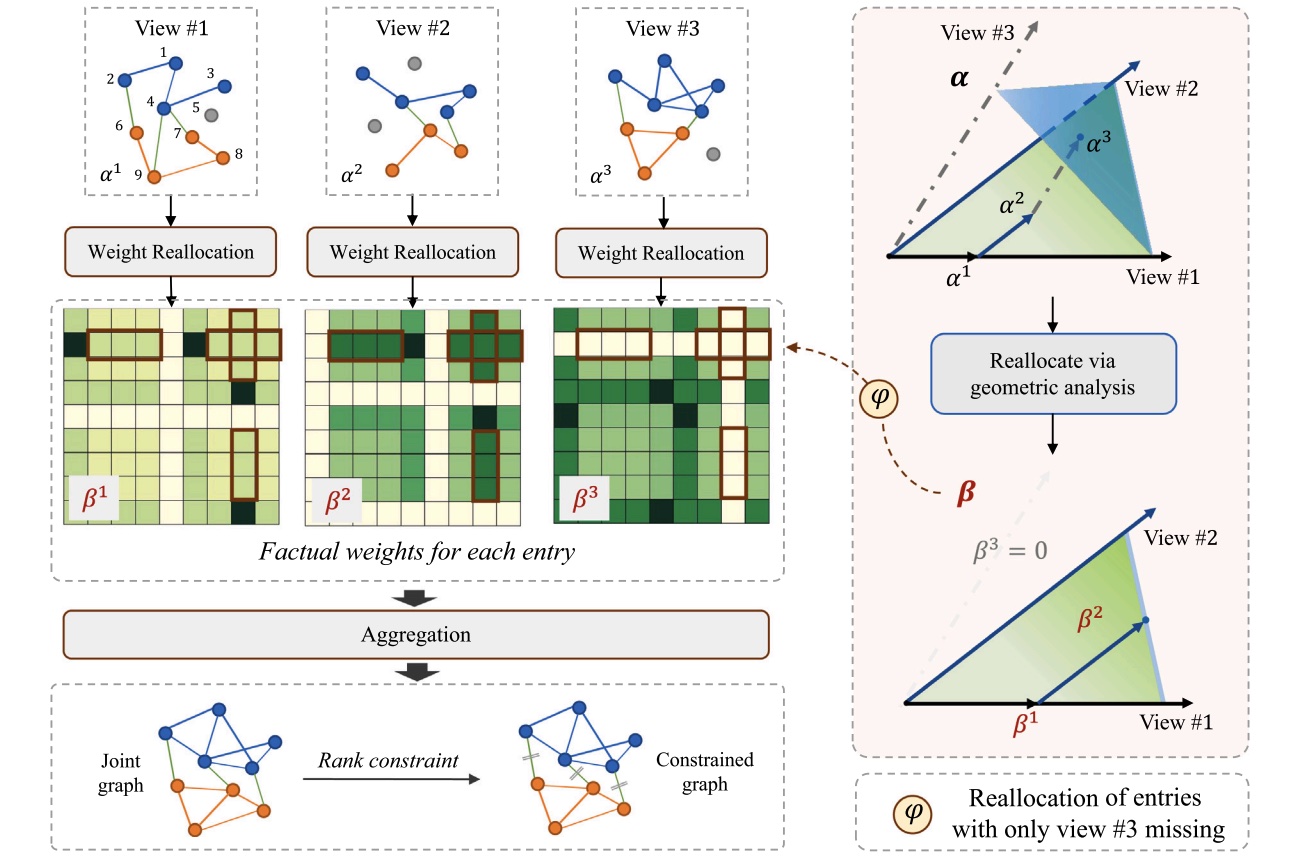
|
Zequn Yang, Han Zhang, Yake Wei, Zheng Wang, Feiping Nie, Di Hu Pattern Recognition, 2023 paper / code Conduct geometric analyses to mitigate missing views in weight aggregation. |
|
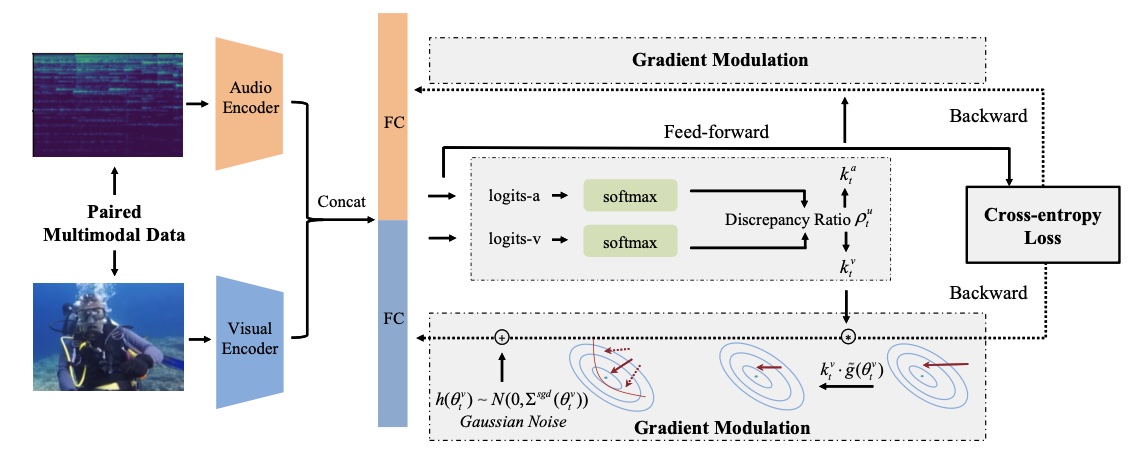
Xiaokang Peng*, Yake Wei*, Andong Deng, Dong Wang, Di Hu CVPR, 2022 (Oral Presentation) arXiv / code Alleviate optimization imbalance in multimodal learning via on-the-fly gradient modulation. |
|
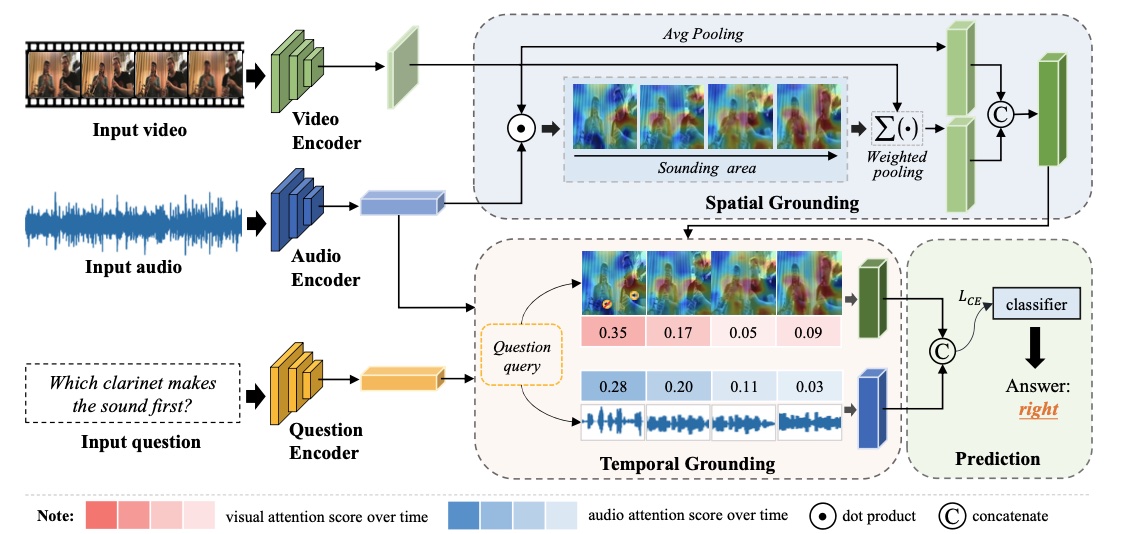
Guangyao Li*, Yake Wei*, Yapeng Tian*, Chenliang Xu, Ji-Rong Wen, Di Hu CVPR, 2022 (Oral Presentation) arXiv / project page Audio-Visual Question Answering and propose MUSIC-AVQA dataset. |
|
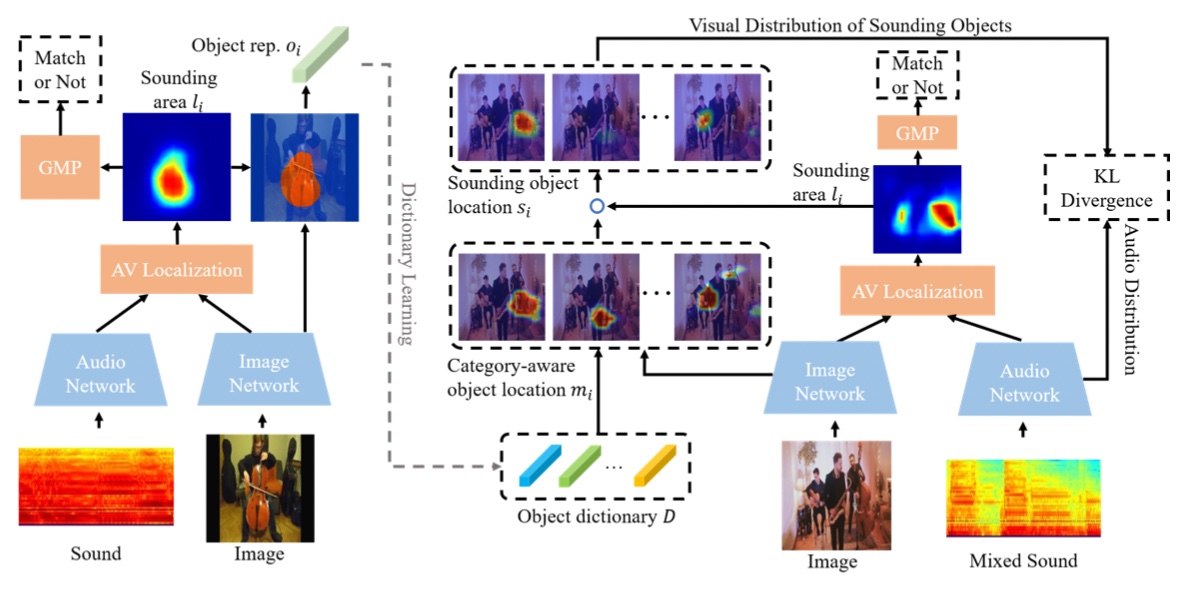
Di Hu, Yake Wei, Rui Qian, Weiyao Lin, Ruihua Song, Ji-Rong Wen T-PAMI, 2021 arXiv / project page Discriminative sounding objects localization. |
|
Updated at Mar. 2026
Thanks Jon Barron for this amazing template.
|